The only thing better than knowing what your customers are doing right now is knowing what they’re going to do before they do it.
Much like the adoption of autonomous vehicles promises to transform how we deal with traffic, the use of predictive analytics in IT is fundamentally changing the way businesses operate. That’s the conclusion of Tim Sandle on Digital Journal.
Widespread use of predictive analytics requires overcoming two obstacles: First, companies are struggling to find IT staff with the right set of skills; and second, analytics are resource-intensive, which drives up costs. Things are getting easier as vendors start to embed AI into software and hardware layers in the IT stack. Here are some other perspectives on how to ensure efficient provisioning of cloud workloads.
The difficulty of calculating cloud total cost of ownership
The bottom-line calculation for any application is total cost of ownership (TCO) when running on-premises vs. TCO on multi-cloud infrastructure. You end up with an apples-to-oranges comparison of operational expenses (hardware/software/maintenance) vs. capital expenses (cloud services for compute, storage, and other resources, plus app rebuild and migration costs).
Being able to assign and track costs to specific users, applications, and clouds is one piece of the puzzle that the multi-cloud orchestration offered by Morpheus can help resolve. Gathering this data in a centralized way is a foundational element for rightsizing.
Tim Lebel writes on InfoWorld that miscalculating TCO causes companies to spend more than they expect on cloud migrations, services, and maintenance. The first step in determining cloud TCO is assessing the workload requirements of your applications in three categories:
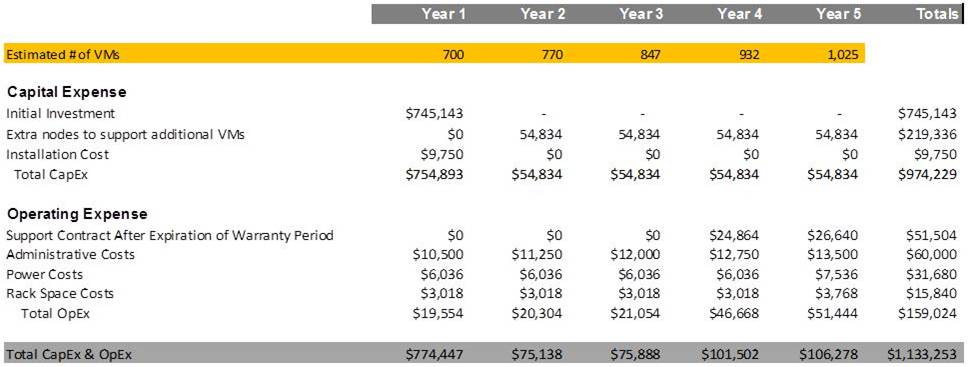
An example cloud TCO calculation forecasts CapEx and OpEx costs over a five-year period for an organization migrating to web-scale infrastructure. Source: Steve Kaplan, via Wikibon
Signs of wasted workload resources
The only way to keep your applications running at peak performance is to determine the optimum instance types and sizes for your workloads. TechTarget‘s Kathleen Casey identifies three measures that indicate a problem related to instances:
Cloud usage reports help you address workload inefficiencies by determining more precisely the memory, virtual CPU cores, or other resources your workloads need.
The general rule is that selecting larger instances will reduce your total instance count, which translates into lower costs. As with most general rules, there are a great number of exceptions. For bursty workloads, long-term instances such as Amazon EC2 Reserve Instances may be best for the baseline load, while larger instance types are used for bursts, and instances from the spot market are applied to other peak loads.
AWS claims its Spot Instances, which are bid on from unused EC2 capacity, can save customers as much as 90 percent compared to the cost of On-Demand Instances. Similarly, Google Preemptible VMs cost up to 70 percent less than the company’s standard instances, although the instances terminate after 24 hours or when the resources are required for other tasks.

Instance performance for hypervisors in EC2 is shown by comparing old virtualization types (top rows) to new types (bottom rows) along with expected performance by resource from most important (CPU, memory) to least important (motherboard, boot). Source: Brendan Gregg
One challenge faced in a multi-cloud world is the fact that every cloud vendor has its own approach to reporting. On-premises infrastructure is often poorly understood. Consolidating cloud management in a unified view can help normalize reporting, as demonstrated by the Morpheus cloud management service’s Intelligent Analytics feature. When coupled with guided recommendations and migration tools, consolidation can cut costs by tens of thousands of dollars per month.
Avoid the most common cloud-overprovisioning mistakes
The number-one cause of companies spending too much on their cloud services is failing to understand how their applications actually operate. On ITProPortal, Yama Habibzai writes that the workload type determines the preferred instance qualities. For example, savings should be greatest for a batch processing job with infrequent high utilization, which is suitable to instances that turn off when inactive so you aren’t paying for CPU cycles you don’t need.
An accurate workload assessment requires applying a statistical model of workload patterns that represent hourly, daily, monthly, and quarterly activity. Keep in mind that many applications are designed to take as many resources as the system makes available. Your reporting tool may recommend boosting CPU resources if utilization stays near 100 percent, but after you provision new resources, you’re back to 100 percent utilization.
This underscores the need to know how your individual workloads function at a granular level. Morpheus Data not only provides this visibility of statistical usage and instance resizing, it also recommends and applies smart power scheduling.
Habibzai points out that knowing how much memory your workloads are consuming won’t prevent overspending. The memory an instance actually requires includes both consumed memory and active memory, as well as the memory set aside for the operating system. The goal is to accommodate a “reasonable amount of caching” while avoiding bloat and ensuring the proper balance between cost efficiency and app performance.
Your cloud budget can be stretched further by taking advantage of new instance types, which are likely to be hosted on newer, higher-performance hardware. This can help you minimize the complexity of services and instance types offered by cloud providers. It also makes it easier to identify and eliminate idle instances without deleting critical batch processing instances that are active infrequently.
A well-thought-out plan minimizes cloud waste
If you’re still on the fence about using multiple cloud services, you’re missing out. Owen Jenkins of research firm Kadence International says the benefits of multi-cloud in terms of efficiency and agility are so significant, the message from users is “just go for it.” A recent study conducted by MIT Technology Review and VMware points out that companies adopting multi-cloud can expect some “growing pains,” as Ty Trumbull writes on Channele2e.
The researchers asked 1,300 IT managers at enterprises around the world about their approach to cloud adoption. The results indicate that organizations can minimize migration glitches by having a comprehensive multi-cloud roadmap. The three greatest challenges to successful implementation of multi-cloud are integrating legacy systems (cited by 61 percent of respondents); the lack of skilled staff (more than 50 percent); and understanding the new technology (61 percent).
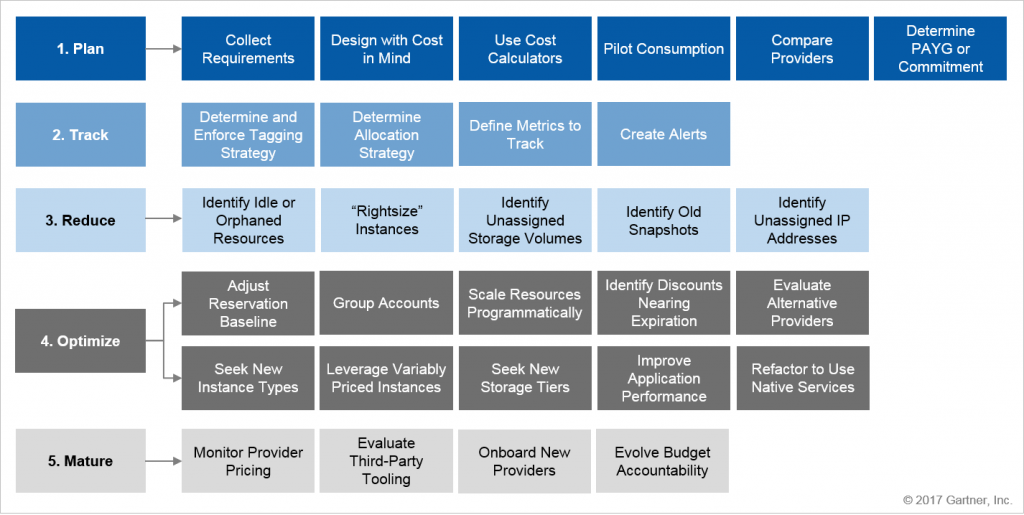
Gartner’s multi-cloud management framework is designed to improve the accuracy of cloud spending estimates based on cloud providers’ price lists, pricing models, discounts, and billing mechanisms. Source: Gartner
Another survey cited by ComputerWeekly‘s Cliff Saran found that 25 percent of businesses aren’t sure what they are spending for public cloud services. In addition, 35 percent of the companies surveyed report that their spending for cloud services exceeded their budgets, and only 20 percent of organizations use automation to optimize their use of cloud infrastructure.
Addressing the two great multi-cloud challenges: Complexity and a lack of skills
The main reason for the uncertainty about multi-cloud is the complexity of the tools AWS, Microsoft Azure, and other large public cloud services offer their customers to keep track of their cloud instances. Using native tools, it’s not easy to determine when instances are used and how much memory, CPU cycles, network bandwidth, and storage they consume.
I mentioned up front that many of these questions are starting to be answered in more holistic fashion as vendors build-in analytics as part of their stack. Examples include how Nimble Storage embedded analytics into their InfoSight platform and how Morpheus Data has embedded it into its multi-cloud orchestration tool.
In both cases, turning analytics into action and leveraging a large historical data set are critical to informing the future. Morpheus provides a unified approach to orchestration for both infrastructure and development teams. Today we expose cloud usage analytics via a single dashboard interface to provide IT managers transparency into how efficiently and effectively their cloud instances are performing.
In the future, we can apply that same analytics engine to the development pipeline efforts of app-centric organizations to help them better understand how different teams are working together and how DevOps toolchains are functioning. We’re in the early stages of the autonomous infrastructure movement. It’s sure to be exciting this year, next year, and into the new decade as this becomes table stakes for management tools.