Someday, something will cause the traffic on your network to spike unexpectedly. Maybe the jump will be the result of a royal engagement, as Canadian fashion company Line the Label experienced late last year. When Prince Harry announced his engagement to Meghan Markle, now the Duchess of Sussex, she was interviewed wearing one of Line the Label’s coats. The ensuing crush of traffic brought down the clothier’s site.
More likely your demand spike will be caused by something mundane, such as a bot attack or run-of-the-mill hardware failure. The best way to prepare for the worst-case traffic scenario is by taking advantage of the scalability and connectability of the cloud.
Information Age‘s Nick Ismail believes what he calls the “Meghan Effect” can be traced to IT departments relying too much on in-house data centers. Ismail writes that any on-premises infrastructure will reach its limit — perhaps sooner than later.
IT managers often cite concerns about cost control and compliance as reasons to keep operations inside their own walls. However, they can’t deny that data resources have never resided solely on-premises: every disaster-contingency plan worth a lick includes complete, up-to-date backups stored far offsite and ready to be restored at a moment’s notice. Today’s hybrid clouds combine the protection of real-time offsite backup with the price efficiency of an on-demand utility.
Make best use of the cloud’s ability to burst
Ismail highlights another capability of cloud computing that IT departments need: the ability to scale out, or “burst” available capacity on demand. If your in-house setup is capable of handling an unanticipated leap in traffic that’s a factor of 10 greater than a typical load, you’re probably spending way too much on hardware.

A typical cloud-scaling scenario uses service agents to detect simultaneous accesses (1), create redundant instances (2), and send an alert when the workload limit has been exceeded (3 and 4). Source: CSDN
The traditional way to accommodate wide swings in network traffic volume is via load balancing done by physical appliances in the data center. Of course, these devices are subject to the same capacity limitations and extended idle times as in-house servers.
Some cloud approaches to load balancing use a virtual version of the physical appliance that’s based on the same architecture as the hardware it replaces. Software load balancers offer near-real-time elasticity that extends from the data center to the cloud. They go one step further by adding application analytics to support predictive auto-scaling.
Morpheus’s physical stack integration combines built-in load balancing with native or third-party monitoring, logging, and incident handling. New load balancers can be brought online automatically to respond almost instantly to sudden, dramatic, and unexpected swings in traffic volumes. In addition, Morpheus’s Intelligent Analytics let you tap into hidden details about how you’re using VMs, containers, and public clouds.
Gauge your network’s burstability via load testing
Any application that is likely to experience wide variations in use patterns needs to be performance-tested under a range of scenarios before it’s deployed. DZone MVB Noga Cohen offers five tips for scaling a site or app to one million users. As you might expect, Cohen’s first suggestion is to give yourself time to work up to load testing your peak anticipated load. In other words, don’t start by testing a million-user load.
The best approach is to incorporate load testing in your continuous integration process. This lowers the chances that a traffic spike will catch you by surprise. In addition to recording all load-test scenarios, you need to remove all resources unrelated to the test so the app doesn’t crash due to a bottleneck that exists in the test environment itself, not in the real world.
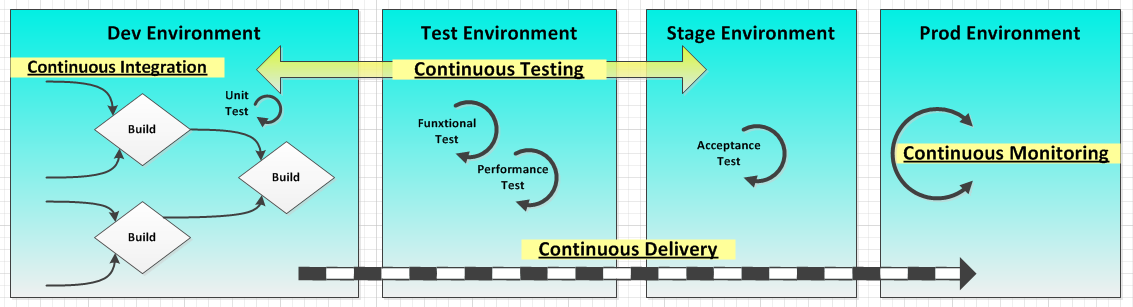
By incorporating load testing in the continuous integration/continuous delivery process, the development and operations teams are linked via self-monitoring and analytics features built directly into applications. Source: Sanjeev Sharma
Finally, analyze each round of load tests in real time, and all test results in the series. Not only will a time-series analysis reveal weaknesses and bottlenecks, the results paint a picture of the system in action as conditions, components, and features change. Of course, the analysis will also confirm that your fixes are effective and complete.
How hybrid cloud’s scalability maximizes the value of your data
In some IT departments, the cloud is treated as nothing more than an extension of the company’s in-house operations. Forbes‘ Adrian Bridgewater writes that “the real power and opportunity lies in the aggregation and analysis of all the information being processed through the cloud.” According to an IT executive quoted by Bridgewater, the primary reason companies are unable to realize the full potential of cloud infrastructure is a shortage of technical expertise.
The scarcity of cloud talent causes many organizations to filter their data analytics through the prism of their in-house tools and processes. They end up with a “hybrid cloud” that is actually two separate and distinct operations: one on-premises and the other in the cloud. John Zanni writes on IT Pro Portal that an efficient hybrid architecture can’t “discriminate between on-premises and cloud environments.”
Tomorrow’s applications will rely more than ever on scalability. The only way to ensure apps running on hybrid clouds can scale on demand is by using cloud-native tools. Machine learning is a prime example of the need to accommodate massive amounts of data dispersed across public and private clouds. EnterpriseTech‘s Kurt Kuckein describes a machine-learning project at the University of Miami’s Center for Computational Sciences that pushed hybrid-cloud scaling to the limit.
The school worked with the city of Miami to implement a hybrid cloud for the collection and real-time analysis of data received at a rate of 10 times per second from more than 100 sensors spread across a 60-square-block area. The goal was to improve public safety for drivers and pedestrians by optimizing the city’s service and maintenance operations. Artificial intelligence projects such as this quickly run into problems as they attempt to scale from prototypes to production.
Typical scaling problems include the inability to provide data access at the speed required for real-time analysis, the failure to maintain a reasonable and cost-efficient data-storage footprint, and outputs that can’t scale because inputs and the deep-learning networks themselves are unable to grow quickly enough.
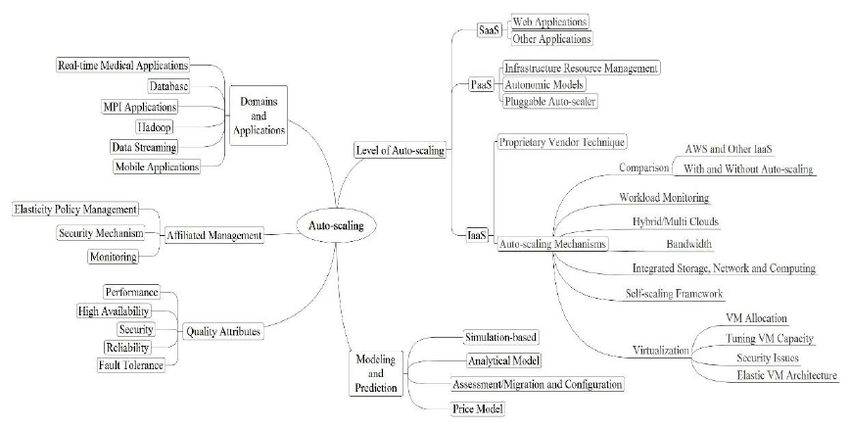
A taxonomy of cloud auto-scaling identifies attributes of auto-scaling for SaaS, PaaS, and IaaS, as well as areas of modeling and prediction (simulation-based, analytical, migration/configuration, and price model). Source: Hanieh Alipour, Xiaoyan Liu, and Abdelwahab Hamou-Lhadj, via ResearchGate
Scaling becomes the foundation of application resiliency
No area benefits more from cloud scaling than disaster recovery. Not long ago, static application deployments in large, centralized data centers required always-on scaling able to accommodate max workloads, as NetworkWorld contributor Kris Beevers writes. Component-level redundancy for specific app and database servers was layered atop the system-wide DR setup encompassing the full application infrastructure. You ended up with a lot of infrastructure sitting idle most of the time.
With cloud infrastructure, DR takes on an entirely new, streamlined complexion. Now thin provisioning and auto-scaling allow resources to be deployed in an instant based on current workloads and conditions. Multi-master database replication systems and global load balancing support active/active setups, the equivalent of switching between two continuously replicated DR configurations.
One danger of auto-scaling is the potential for overspending on cloud services. InfoWorld‘s David Linthicum identifies over-reliance on auto-scaling and auto-provisioning services as a prime reason why companies burn through their cloud budget quicker than they planned. When you allow a public-cloud provider to determine the resources your apps need for optimal performance, it’s like handing the service a blank check.
To ensure your multi-cloud setup is delivering the perfect mix of performance and resource consumption, take advantage of the dashboard interface and easy-to-configure alerts offered by the Morpheus unified cloud management service. For example, Morpheus’s Intelligent Analytics let you view monthly costs by cloud, and instance types by cloud and by group (for memory, storage, and CPUs/cores). You can view and compare public-cloud costs to ensure your workloads are mapped to the best infrastructure.
That’s hybrid-cloud scaling that both the CIO and the CFO will appreciate.