Two of the greatest challenges IT departments face when managing cloud data are latency and compliance. By ensuring that the data and apps you place on cloud platforms are designed to know and report their physical location, you make your data caches more efficient, and you meet regulatory requirements for keeping sensitive data resources safe.
Virtualization has transformed nearly every aspect of information management. No longer are the bulk of an organization’s data and applications associated with a specific physical location. The foundation of public cloud services is the virtual machine — a nomad data form that appears whenever it’s needed and runs wherever it can do so most efficiently and reliably. The same holds true for VMs’ more-compact counterpart, containers.
You may be inclined to infer from the rootlessness of VMs that it no longer matters where a particular data resource resides at any given time. Such an inference could not be further from the truth. It’s because of the lack of a permanent home that IT managers need to be tuned into the physical context in which they operate. In particular, two important management concerns cry out for location awareness: latency and compliance.
Location awareness boosts cloud response times
If intelligent caching is important for optimizing the performance of in-house machines, it is downright crucial for ensuring peak response times when caching cloud systems. TechTarget‘s Marc Staimer explains that cloud storage needs to be aware of its location relative to that of the app presently reading or writing the data. Location awareness is applied via policies designed to ensure frequently accessed data is kept as close as possible to the app or user requesting it.
Keeping data close to the point of consumption can’t be done efficiently simply by copying and moving it. For one thing, there’s the time and effort involved. You could be talking about terabytes of data for a large operation, and even multiple smaller migrations will take their toll on performance and accessibility. More importantly, the data is likely being accessed by multiple sources, so location awareness needs to support dispersed distributed read access.
An example of maximizing location awareness to enhance cloud elasticity and reduce latency is the Beacon framework that is part of the European Union’s Horizon 2020 program. After initial deployment on a private cloud, an application’s load may be dispersed to specific geographic locations based on user and resource demand. The new component is placed in the cloud region that’s closest to the demand source.
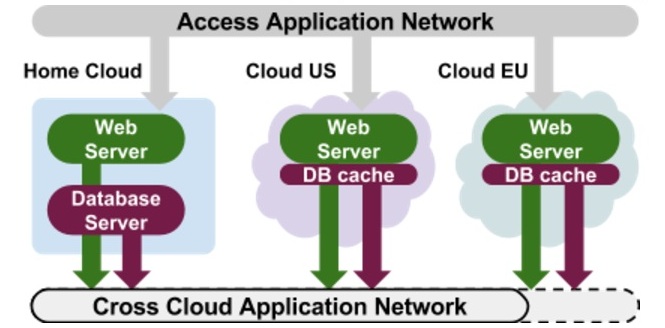
Location aware elasticity is built into the EU’s Beacon framework, which is designed to reduce cloud latency by placing data resources in cloud regions nearest to the users and resources accessing the data most often. Source: Beacon Project
Addressing cloud latency via proximity is the most straightforward approach: choose a cloud service that’s located in the same region as your data center. As CIO’s Anant Jhingran writes in an April 24, 2017, article, the choices are rarely this simple in the real world.
A typical scenario is an enterprise that keeps backends and APIs in on-premise data centers while shifting management and analytics operations to cloud services. Now you’re round-tripping APIs from the data center to the cloud. To reduce the resulting latency, some companies use lightweight, federated cloud gateways that transmit analytics and management services asynchronously to the cloud while keeping APIs in the data center.
Confirming residency of cloud data regardless of location changes
The efficiencies that cloud services are famous for is possible only because the data they host can be relocated as required to meet the demands of the moment. This creates a problem for companies that need to keep tabs on just where sensitive data is stored and accessed, primarily to ensure compliance with regulations mandating preset security levels. These regulations include HIPAA in the U.S. and the forthcoming European General Data Protection Regulation (GDPR), which takes effect in May 2018.
Researchers at the National University of Singapore School of Computing have developed a method of verifying the residency of data hosted on any cloud server (pdf). Rather than depend on audits of the servers used by cloud providers to confirm the presence of specific data, the new technique verifies residency of outsourced data by demanding proof that each file is maintained in its entirety on the local drives of a specific cloud server.
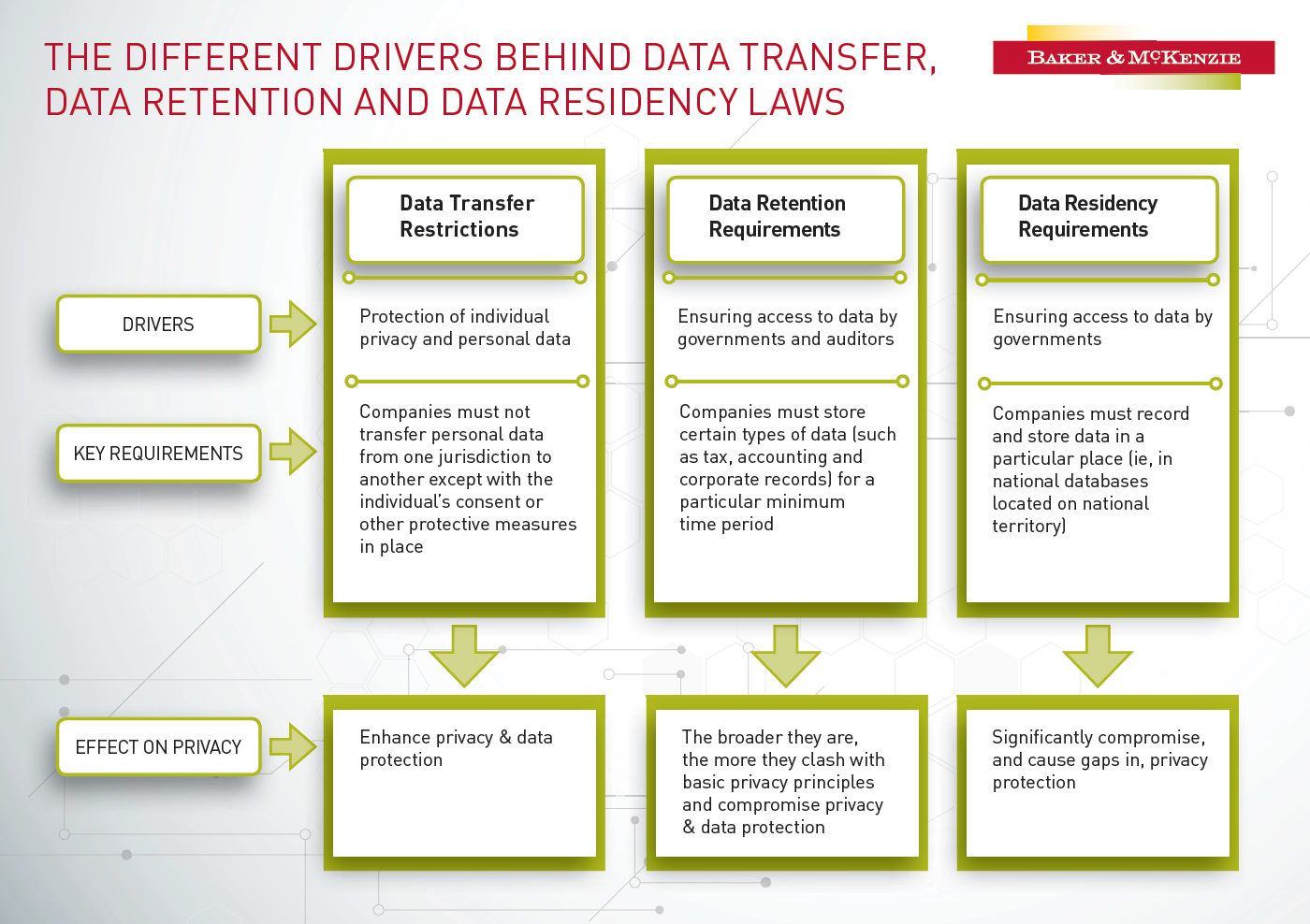
Government data residency requirements differ greatly from data transfer requirements and data retention rules; some residency requirements may compromise data protection rather than enhance it. Source: Baker McKenzie Inform
The researchers contend that data residency offers greater assurances than approaches that focus on the retrievability of the data. The technique enhances auditing for compliance with service level agreements because it lets you identify the geographic location of the cloud server a specific file is stored on. That level of identification is not possible with after-the-fact auditing of a cloud service’s logs.
Another advantage of the data residency approach is the ability to verify simultaneously replications of data on geographically dispersed cloud servers. The Proof of Data Residency (PoDR) protocol the researchers propose is shown to be accurate (low false acceptance and false rejection rates) and applicable without increasing storage or audit overhead.