A big part of an IT manager’s job is asking, “What if…?” As cloud services become more popular, disaster plans are updated to include contingencies for the moment when the company’s cloud-hosted data resources become unavailable.
Two recent service failures highlight the damage that can result when a cloud platform experiences an outage:
The proactive approach to mitigating the effects of a cloud failure
If you think the threat of an outage would deter companies from taking advantage of cloud benefits, you obviously haven’t been working in IT very long. There’s nothing new about ensuring the high availability of crucial apps and data when trouble strikes. On the contrary, keeping systems running through glitches large and small is the IT department’s claim to fame.
NS1’s Alex Vayl explains in an article on IT Pro Portal that the damage resulting from an outage can be greatly reduced by application developers following best practices. Vayl identifies six keys for designing and deploying high availability applications:
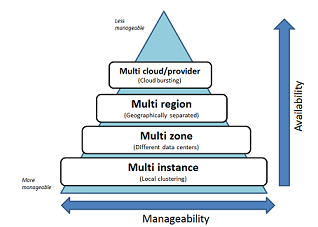
The cloud lets you implement abstraction at the infrastructure, platform, or application level, but improving availability via multi-zone, multi-region, or multi-cloud increases management complexity. Source: Cloudify
Redundancy nearly always adds to the cost and complexity of cloud networks. However, the expenses incurred as a result of a prolonged network outage could dwarf your investment in redundant data systems. The best way to minimize the risk of a catastrophic system failure is by eliminating single points of failure. The best way to avoid single points of failure is by investing in redundancy.
In other words, you can pay now for redundancy, or pay later for massive data losses.
Getting a grip on the ‘three vectors of control’
Preparing for a cloud service outage isn’t much different than getting ready for any system failure, according to HyTrust’s Krishnan. No matter the nature of the network, there will always be three pinch points, or “vectors of control,” that managers need to master.
The first is scope, which is the number of objects each admin or script is authorized to act upon at a particular time. Using the Microsoft outage as an example, a deployment task’s scope would limit the number of containers it could operate on at one time.
The second control vector is privilege, which controls what type of action an admin or script (task) can take on an object. An example of a privilege restriction would be a task that is allowed to launch a container but not to destroy one.
The third control point is the governance model, which implements best practices and your policy for enforcing the scope and privileges described above in a “self-driven” manner. For example, a governance policy would limit the number of containers an admin or script can act on at one time to no more than 100 (scope) while also providing a predefined approval process for exceptions to the policy.
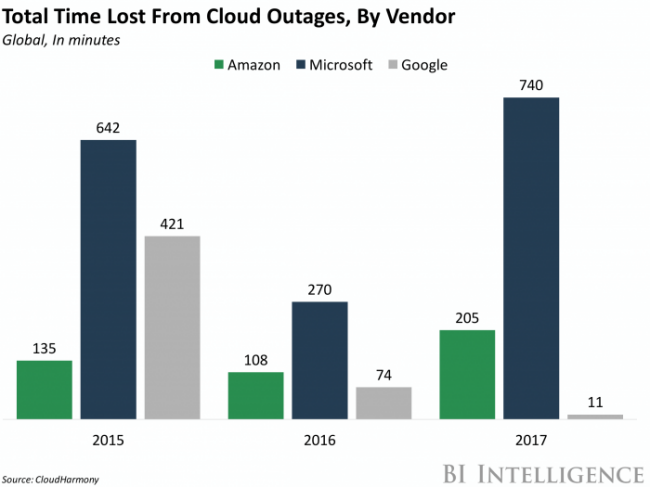
Despite the highly publicized outage of February 28, 2017, AWS has experienced much less downtime than cloud-platform competitors Microsoft and Google. Source: The Information
Multi-cloud’s biggest selling points: Backup and redundancy
The major cloud platforms — Amazon, Microsoft, and Google — have different attitudes about transferring data between their respective systems. Google’s new Cloud Endpoints API is designed to integrate with AWS’s Lambda function-as-a-service product, as NetworkWorld’s Brandon Butler writes in an April 27, 2017, article. This allows you to use Endpoints to manage API calls associated with a Lambda application.
Among AWS’s cloud connectivity products are Direct Connect, Amazon Virtual Private Cloud, and AWS Storage Gateway; coming soon is an easier way to run VMware workloads in AWS clouds. Yet AWS executives continue to downplay the use of multiple clouds, even for backup and redundancy. They insist it’s easier, less expensive, and just as effective to split your workloads among various regions of the AWS cloud.
Many analysts counter this argument by pointing out the future belongs to multi-cloud, primarily because of the approach’s built-in redundancy and resiliency in the event of outages — whether caused by human error or a natural disaster. Butler suggests that one way to hedge your bets as the multi-cloud era begins is to adopt a third-party cloud integration tool rather than to rely on your cloud provider’s native tools.
(For a great primer on everything multi-cloud, check out TechRepublic’s “Multi-cloud: The Smart Person’s Guide,” published on May 4, 2017.)