
If you believed everything you read, you’d think the cloud would single-handedly save the world and everything in it. When you cut through the hyperbole and look solely at results, you find that two of cloud services’ traditional strengths remain the key to their success. 1. The ability to scale compute, network, and storage resources dynamically and automatically, and 2. The security benefit, which is that automatic backups can be stored safely apart from potential threats, whether they be natural disasters or of the human-made variety.
Nobody could be blamed for thinking the “(fill-in-the-blank) as a service” hype has gotten way out of hand. Now that “everything as a service” and “anything as a service” have arrived, you would think the as-a-service possibilities had run their course.
But no. Recent permutations include education-as-a-service (which shares an acronym with email-as-a-service), delivery-as-a-service, and food-and groceries-as-a-service. Can dog grooming-as-a-service be far behind? (Don’t tell me – it’s already been done… somewhere.)
One more as-a-service pitch and your local IT manager is likely to drop a rack of idle servers on your head. It’s time to cut through the chatter and get to the heart of cloud-service advantages: more efficient use of your hardware, software, and human resources. The two cloud features that deliver the greatest efficiency bump for most organizations are auto-scaling and automatic backups.
If only auto-scaling your cloud services were as easy as pressing a big red “Scale” button. Amazon Web Services claims that its CloudWatch metrics let you scale EC2 instances dynamically, or if you prefer, you can set your own schedule for resource-demand peaks and valleys. In practice, however, AWS’s Auto Scaling sometimes fails to live up to its billing. In a September 2015 article, TechTarget’s Chris Moyer describes a situation in which AWS servers were still running, even though their services had stopped and would not restart.
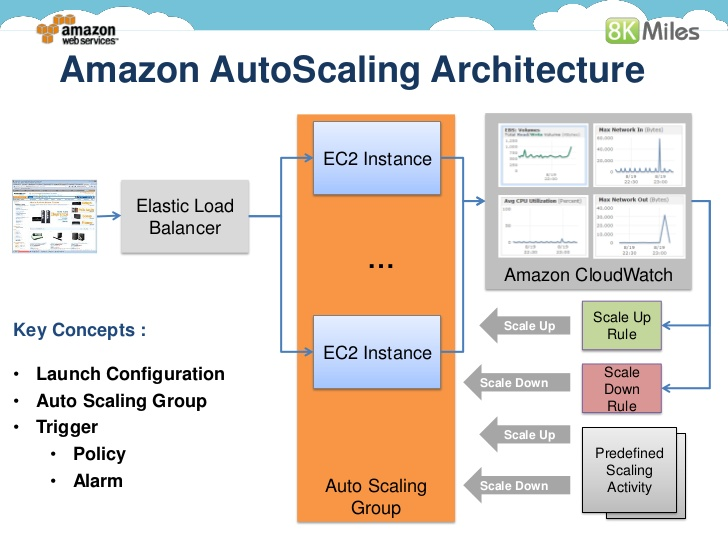
AWS Auto Scaling works in conjunction with an elastic load balancer and the CloudWatch service to match resources to workloads, but some stopped services may not be detected on running servers. Source: Harish Ganesan, via Slideshare
Once the server stopped serving up requests, the Elastic Load Balancer (ELB) would disconnect from it. However, the AWS Auto Scaling group wouldn’t replace the server because it was still running. When the service ultimately stopped because all the servers were affected by the problem, Auto Scaling didn’t detect the problem, so it didn’t send an alert that the service failed and wouldn’t restart. The glitch could have been avoided if ELB health checks had been used in addition to EC2’s own health checks.
In Moyer’s case, a problem with the Auto Scaling group configuration was causing a server to be killed and relaunched continuously: Every 5 minutes a new server was launched and an old one was ended. Since the minimum billing time for each AWS instance is one hour, the constant stopping and starting was increasing the tab by a factor of 12. (Once the discrepancy was discovered and the problem fixed, Amazon credited the resulting overcharge, as well as similar overpayments in the two previous months.)
To prevent such constant relaunches, Moyer recommends subscribing to notifications on Auto Scaling groups. When you find that AWS is spinning up and replacing servers unnecessarily, either disable an availability zone or stop the group from executing any actions. You also have to make sure ELB is giving servers a sufficient grace period before deciding the server isn’t starting correctly.
Morpheus’ app and DB management service, makes it easy to avoid having your auto-scaling operations run amok. For example, Morpheus’s Instance Summary Panel shows three types of status graphs: Memory (cache, used, and max), Storage (used and max), and CPU (system and user). The server summary also lists all containers, including the name, location, type, IP address, port, memory, storage, and status of each. You can instantly stop, start, or restart an instance via the panel’s drop-down menu.
You never know what hazard will be the next to threaten your organization’s most important data. In a November 15, 2015, article, security expert Brian Kreps reports on the latest iteration of ransomware that targets websites hosted on Linux servers. In April 2015 CheckPoint identified the vulnerability in the Magento shopping-cart software that the virus writers exploited, and a patch was released soon thereafter. However, many ecommerce sites remain unpatched, and sites continue to be victimized by the ransomware, according to Krebs.
The best defense against ransomware and other data risks is to back up all critical data automatically to a secure cloud-backup service. As IT Pro’s Davey Winder reports in a November 17, 2015, article, the FBI took much heat when the agency recommended that victims of ransomware simply pay the ransom. While that may free your hostage data in the short term, it empowers and emboldens the cybercriminals to target even more of your sensitive data – and to demand higher payoffs to liberate it. Of course, there’s always the risk that the crooks will take the money and run – without releasing your data.
Winder is one of several security analysts who recommend strongly that you never pay ransom for your hostage data. It’s safer, cheaper, and more socially responsible to simply restore your data from your near-real-time backup. The standard advice is to have both local and cloud backups, but the key is to have at least one current backup of all important data that is “air-gapped,” meaning it has no connection – wired or wireless – to the computers and networks that are at risk of infection by ransomware.

The CryptoWall ransomware continues to infect systems around the world. As of late 2014 the virus had infected more than a quarter million systems in the U.S. alone. Source: Dell SecureWorks
Cloud backups of your critical apps and databases don’t get simpler, safer, or more efficient than those you create automatically via the Morpheus service. Not only does Morpheus automatically collect system, application, and database logs for all provisioned systems, each new app or database stack component is backed up automatically. You can define the frequency of your backups, as well set the destination (local or cloud) without having to write custom cron jobs.
Cloud management services such as Morpheus are increasing in popularity for a very good reason, or rather for three very good reasons: efficiency (resource consumption increases and decreases as your needs dictate); availability (access your apps and data from any location); and security (protect your valuable data assets from natural and human-made threats). That’s a prospect IT managers are finding more and more difficult to ignore.
To see what Morpheus can do for you, click here to sign up for a FREE 30-day trial.